Zum Geleit: http/2 ist der aus SPDY hervorgegangene Nachfolger von http 1.1, das einige Vorteile mit sich bringt. Während http 1.1 ein File nach dem anderen rauswirft, je nach Filetype vielleicht komprimiert, und immer nur das, was der Client anfordert, macht http/2 da einen einzigen, binären Stream draus, komprimiert http-header, kann aktiv per Push gleich mitschieben, was der Client zum rendern braucht, aber noch nicht weiß, und läuft nebenbei standardmäßig verschlüsselt. Alle modernen Browser können http/2, und laut Wikipedia ist der aktuelle Durchdringungsstand bei den Webseiten grade bei um die 12%.
I can haz http/2
Stellt euch nun mein Erstaunen vor, als ich feststellte, ich trage mein Scherflein dazu bei. Die korrupt.biz (und diverse weitere Sites auf meiner Kiste) liefern bereits fröhlich http/2 aus und ich wusste nichts davon. Wie kommt das? (also das Nichtmitkriegen – die Servereinstellung wird ein Plesk-Default sein, der mit SSL aktiv wird) – Weil http/2 irgendwie seit 2015 so über den Wassern schwebt, so in der „HTTPS jetzt, alle!“-Welle und der AMP-Debatte dann aber ein wenig unterging, man es nirgends so recht sieht, wenn wo http/2 rennt, weil Google nie so richtig gesagt hat, jetzt aber, und vor allem: man merkts selber nicht und die Standardtools, selbst die bezüglich Speed/Ladezeiten erzählen allenfalls sehr versteckt davon.
Ob der Googlebot inzwischen http/2 kann, ist mir nicht bekannt. Das „konkreteste“, was mir diesbezüglich über den Weg lief, war folgendes Statement vom Search Console-Team:
Setting up HTTP/2? Go for it! Googlebot won't hold you back.https://t.co/3bf5Kd2Eo8
— Google Webmasters (@googlewmc) December 19, 2016
Das will nichts heißen, es wurde vereinzelt als „er liests jetzt“ interpretiert, was mir ein bißchen gewagt vorkommt. Auch ansonsten weiß ich wenig, was den „echten“ http/2-Auslieferprozess einer Seite darstellt. Für Chrome gibts den http/2 und SPDY Indicator, der zeigt an, ob ne Seite per http/2 oder SPDY ausliefert, dasselbe von Cloudflare, da heißts Claire. Darüber stieß ich auch auf die (auch ohne die Extension aufrufbare) http/2-Eventcapturer-Anzeige von Chrome: die zeigt die laufenden http/2-Prozesse. Dafür einfach in die Browserzeile chrome://net-internals/#http2 reinwerfen.
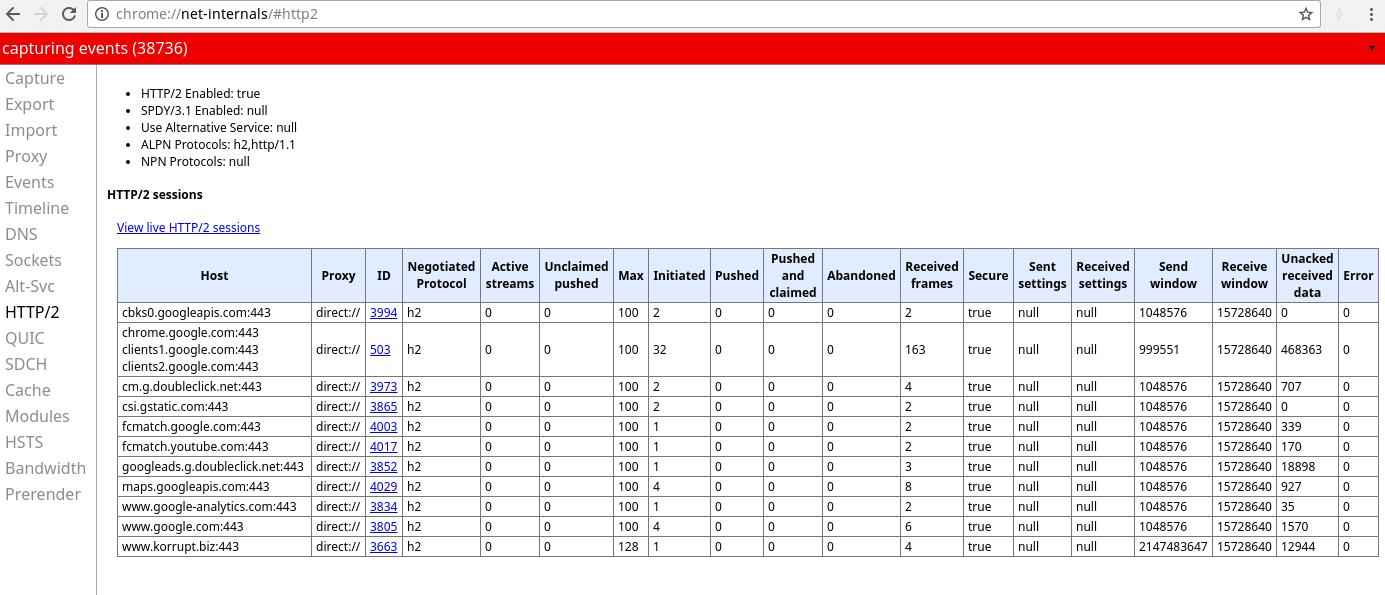
http2-Sessions via Chrome

http2-Log via Chrome, zwei Browserfenster
Dort lassen sich einzelne Prozesse anklicken und separat betrachten. Zwei Browserfenster, und mal rennenlassen: sieht man direkt, wie die Pushaktionen, Nachladeaktionen im gleichen Prozess usw. kommen. Nur: wenn ich das mit den Developertools ansehe, krieg ich meinen normalen Waterfall. Wenn ich das in webpagetest.org checke, kriege ich den auch. Wenn ich kein Keepalive habe, monierts Webpagetest, obwohl es über http/2 an sich vollkommen wurst sein müsste, weil ja schließlich eh nur noch ein Binary-Stream durch eine Pipeline gehen muss und nicht etwa 20×5 einzelne Dateianforderungen an den Server geschickt und einzeln abgearbeitet werden.
Dass bzw. wo http/2 ausgeliefert wird, kriegt man via Entwicklertools im Browser auch noch mit: dafür muss man nur die Spalte „Protocol“ unter „Netzwerk“ aktivieren. Aber auch hier: Waterfall, als ob der Browser die Geschichte intern wieder wie http 1.1 handhabt. Ich kanns ehrlich gesagt nicht recht einordnen.
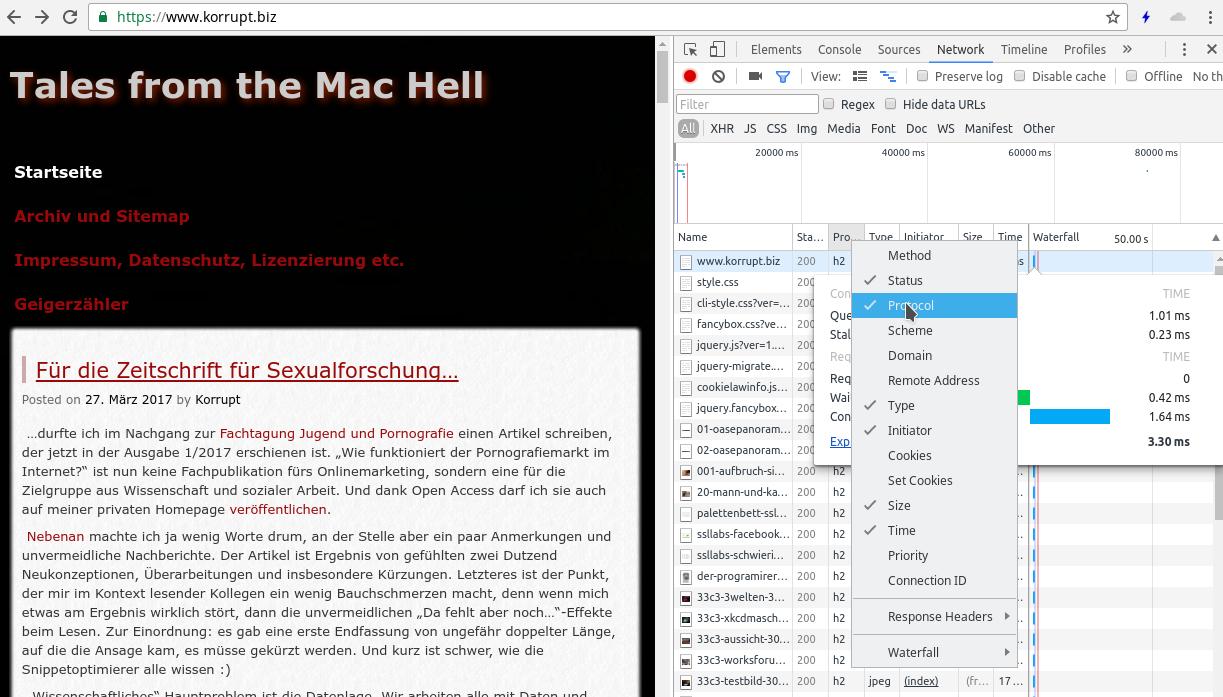
Entwicklertools, mit Protokoll-Zusatzspalte
Noch einige Tools und http2 explained für das deepere understanding of things liefen mir noch über den Weg, letzteres im Kontext von „Curl auf Mac ist noch zu alt, um schon curl –http2 zu können“ und dem daheim folgenden „Argh, Curl auf Kubuntu ist genausoalt und kanns auch nicht“.
Prinzipiell aber mein Gegrübel: faktisch haben wir eine ganze Latte von Seiten bzw. die Möglichkeit für eine ganze Latte selbiger, die einfach deutlich flotter ausliefern zu lassen. Und alle Welt ruft, Yay, http/2, für SEO bringts direkt wahrscheinlich nichts, aber Speed ist immer gut und das wird Google honorieren“, allein, ich frage mich, obs Google überhaupt *mitkriegt*. Wenn der Bot kein http/2 abrufen kann, nun ja, Infos zu Seitenladezeiten wird Google auch aus anderen Quellen kriegen, allein, mir fehlt der Glaube, dass das dann eine große Rolle spielen soll.
Weiß wer mehr, denkt sich wer was anderes und klügeres dazu? Mir kommts grade ein wenig vor wie „Nicht verkehrt, wenns geht, reinhauen, aber man wird aktuell nicht viel messbares haben, um Resultate einzuordnen“.