
In den letzten Wochen grübelte ich einiges zum Thema ChatGPT, Bard und generell den LLMs, die grade diverse Branchen aufmischen. Naturgemäß schau ich aus der SEO-Ecke drauf und muss zugeben, nicht so recht die Finger draufzukriegen. Insofern, eine Latte Gedanken (hoffentlich einigermaßen klug) und viele offene Fragen (hoffentlich einigermaßen spannend).
Um kurz zu umreißen, wo ich entlangdenken will:
Ich gehe davon aus, das LLMs/AIs bereits jetzt stupide Text- und Grafikjobs erledigen, das eine Gute Sache sein kann, und weiter durchaus auch Kreativität der menschlichen Akteure in den entsprechenden Branchen fördern können. Gruselig wird die Kiste in Richtung „Spammen der Diskurse“ und genereller Manipulation, rechtlich wird die Rechtslage in Sachen Trainings- und Ergebnisdaten noch witzig. Spannend scheint mir, wer letztendlich damit Geld verdienen kann bzw. wird und womit (siehe auch den Google-Leak zum Thema, wo das „Wir können nix damit verdienen!“ der etwas unbeachtete Elefant im Raum von „Himmel, das können jetzt alle, und womöglich besser als die üblichen Verdächtigen“ ist.)

Knowledge Graph-Strukturen. Alt und bewährt!
Aus der SEO-Perspektive seh ich LLMs unverändert als weitgehend untauglich für eine zuverlässige Wissensorganisation bzw. -aufbereitung. „AI“ lass ich da bewusst weg, siehe unten. Zentrales Problem scheint mir da die „stochastische“ Grundlage des ganzen Modells zu sein. Und was ich absolut nicht verstehe ist, warum in der ganzen Diskussion um die Relevanz und Zuverlässigkeit LLM-generierter Inhalte nie die Rede von Knowledge Graphen ist. Bzw., ich hab die Privathypothese, dass ein KG eben ein komplett anderer Ansatz ist, den man nicht eben mal an ein LLM anflanschen kann.
Einer draufgesetzt: ganz tapfer vermute ich, dass Google genau deswegen von OpenAI/ChatGPT auf dem falschen Fuß erwischt wurde, weil sie die rein stochastische Contentgenerierung da nicht als „Endnutzerschnittstelle“ in Erwägung gezogen haben und insbesondere ihr Kernprodukt (Suche/Informationsaufbereitung) massiv von Knowledge Graph-Strukturen geprägt ist. Was mir im Übrigen vollkommen einleuchten würde, weil sich aus KGs eben verifizierbare Aussagen ableiten lassen, Strukturen gezielt angelegt und geändert werden können (und müssen), während LLMs eben wie gehabt stochastisch funktionieren und der Trainingsprozess zumindest verglichen mit einer KG-Struktur eine sehr schwarze Blackbox ist. Aber von vorne.
LLMs/AI, stupide Textjobs und kreativer Einsatz
Ich verfolge die Debatte um LLMs durchaus und ahne, dass hier durchaus kein „Blockchain 2.0“ im Sinne eines „Eine Lösung auf der Suche nach einem Problem“ am Start ist. Usecases galore, das Problem ist allenfalls die Technikfolgenabschätzung. Wer sich an Clickworker/Textbroker-Aufträge der Art „100 mal 500-800 Wörter über Gewinnspiele bitte“ erinnert, wird Potentiale ahnen. Dass wir in absehbarer Zeit Strategien zum Umgang mit LLM-Fluten an der Uni, in Onlineshop-Artikelbeschreibungen, in der Sportberichterstattung, in Social Media, generell im Web oder auf Wikipedia, whatever brauchen: Ja. Sehr entschieden Ja, aber das zeigt nur, dass die Technik per se natürlich hoch anschlussfähig ist. Was uns aber direkt zur folgenden Problemstellung führt, zu
LLMs/AI und Wissensorganisation bzw. -aufbereitung
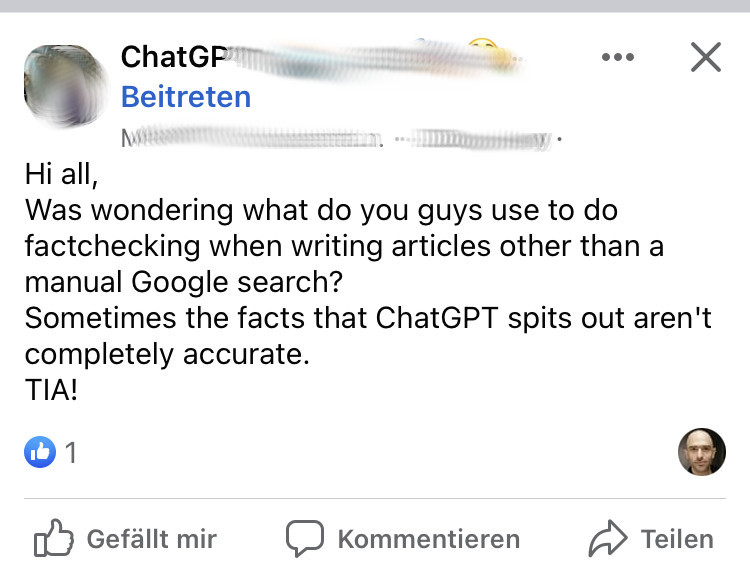
YOU_DONT_SAY.JPG
Es besteht meiner Ansicht nach Einigkeit darüber, dass LLM-generierte Texte nicht verlässlich sind. Man mag sich streiten, ob das nicht für alle Texte gilt, aber allein der Aspekt der Zuschreibe- und Überprüfbarkeit sticht hier meiner Ansicht nach. Das macht meiner Ansicht nach auch die Tragik der ganzen Geschichte aus: man hat ein Tool, das insbesondere „fürs Kreative“ taugt und gerade bei den mühsamen Jobs tendenziell versagt.
Ich halte das für ein systemisches Problem: das „stochastische“ Prinzip ohne inhaltliches Verständnis. LLMs generieren Wortfolgen auf der Basis von Wahrscheinlichkeiten und die beste Beschreibung des Prinzips schien mir der knappe Satz „Was könnte wie eine Antwort auf Aufgabe X aussehen?“. Tatsächlich ist der Bing-Chatassistent da durchaus nicht schlecht unterwegs und insbesondere kann er Quellen angeben, aber auch hier hat man eben das Prinzip „Welcher Link könnte wie eine Quelle für X aussehen?“ Der Bot weiß nicht, dass Link X ein Beleg für Aussage A ist, er hat nur gelernt, dass Links wie X statistisch häufig zur Belegung von Aussagen wie A verwendet werden. Und in dem Kontext bzw. als Kontrast folgend das SEO-Elend einer spezifischen Art von Google-SERP, die mir in der Vergangenheit das Leben schwermachte, aber die – wenn man nicht für eine Kinokette optimiert – einen verdammt guten Job für die Nutzer macht:
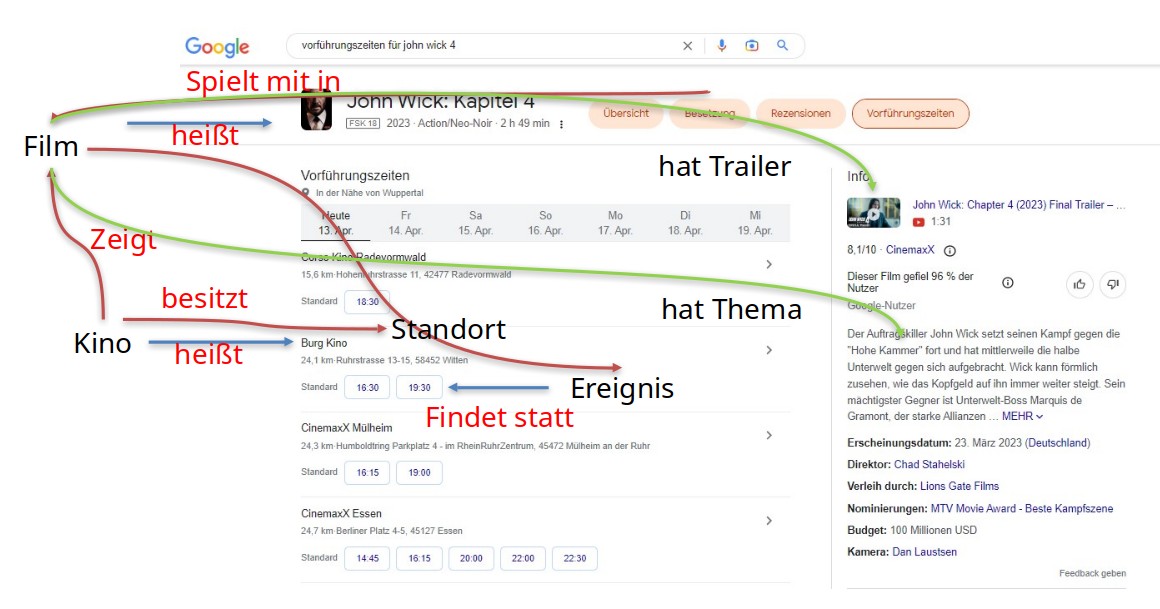
Knowledge-Graph-Strukturen in Google-SERPs, Beispiel John Wick 4
LLM vs. Knowledge Graph und Googles falscher Fuß.
Was wir hier sehen, ist eine Verknüpfung verschiedener Entitäten in einem Knowledge Graph. Das ist im Übrigen ein vergleichsweise alter Hut und seit den Altvorderen die Basis von Googles Knowledgegraph-Panels. In extremer Kürze: ein KG stellt definierte Beziehungen zwischen Entitäten her. Keanu Reeves spielt in John Wick 4 läuft am Datum 13.4. im Ort CinemaXX in Mülheim hat eine Adresse am Humboldtring. Und nun kann man sichere Aussagen ableiten: Halb fünf am Humboldtring Mülheim kann man Keanu Reeves sehen.
Ich bin recht sicher, man wird sich bei der Kinoplanung nicht auf ChatGPT verlasssen bzw. sich zumindest einen Assistenten wünschen, der solche logischen Verknüpfungen machen und verifizieren kann. Und da sind wir bei meiner Kernvermutung: Google hat die „rein stochastische“ Usability von LLMs massiv unterschätzt und hat sich auf KI-gestützte Auswertung von KGs konzentriert (btw., für ihr Kernprodukt „Suche“ durchaus zurecht). Die Basistechnik von LLMs ist grundverschieden von einem KG-gestützten Ansatz, aber – so meine starke These – den braucht man aber, wenn man verifizierbare Informationen ausgeben will. Nun zeigte ChatGPT, dass das Produkt direkt in den Hype geht, auch ohne inhaltliche Zuverlässigkeit. Fast noch schlimmer: Bing zeigt, dass sogar sowas wie Quellennachweise simuliert (ich sag mit Bedacht nicht „geliefert“) werden können. Resultat: Panik bei Google, auch wenn ich der festen Ansicht bin, sie liegen eigentlich richtig und die LLM-Technik ist für ihr kernprodukt (Suche, Wissensorganisation) nicht zu gebrauchen.
Ob die „Wahrheitsprobleme“ von LLMs grundsätzlich lösbar sind, kann ich nicht wirklich einschätzen. Ich würde in eine Richtung dahingehend denken, dass auf eine Frage/einen Arbeitsauftrag zunächst ein „wahres Gerüst“ an Entitäten und Beziehungen gebaut werden müsste, dass der eigentliche Chatbot dann nur noch „ausformuliert“. Ein KG-basierter KI-Bot wär ein Knaller, ich bin aber ziemlich sicher, dass man das aufgrund der grundverschiedenen Ansätze eben nicht einfach das eine ans andere rangeflanscht bekommt.
Um noch nen Schlenker zur Content-Seite zu machen: ich rede grade immer nur über Googles Optionen, LLM für Suche/Resultate einzusetzen/als Schnittstelle anzubieten. Die Seite der Contentlieferanten hat es tatsächlich leichter und ich gehe davon aus, dass sich hier „Wahrheitsprobleme“ zumindest ein Stück weit kleinoptimieren lasssen, wenn man die Trainingsdaten entsprechend feineinstellt. Das ist auch einer der Knackpunkte an der ganzen „Scheiße, LLM-Technik ist OS und wird Allgemeingut“, ich nehme an, es ist einfacher, einen KI-Assistenten mit einem überschaubaren Korpus zu trainieren und für exakt dieses Feld dann vernünftigen (aber halt nicht originellen) Kram abzusondern, während die „Universalbots“ a la Bard eben da weniger gut „anzuspitzen“ sind.
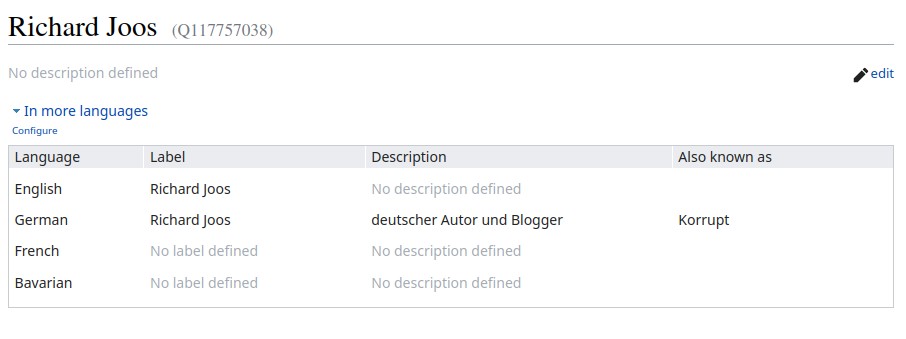
Ich bin drin!
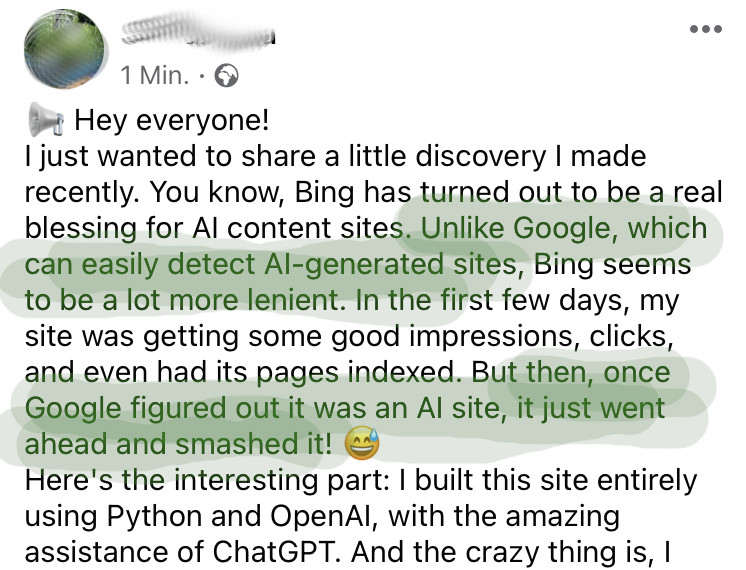
Aber unironisch: Respekt, Google
Will ich mit sowas arbeiten? Ach, ein Helferlein könnts werden. Aber die KG-basierten Aussagen kriegt man jedenfalls einigermaßen zuverlässig in die SERPs, wohingehend Google sich beim Erkennen von Contentspam durchaus ein paar Meriten erworben hat. Um nach der Hypothetisiererei noch ein wenig konkreter zu werden: das bereits rauf- und runterdiskutierte Statement, durch LLMs werden Autorensignale wieder relevanter, würd ich unterschreiben. Und entsprechend wird man (lies: ich) gucken, was mit der Netzidentität verknüpft so alles scharfgeht.
7 Responses to Gedanken zu LLM/AI, ChatGPT/Bard und Knowledge Graphs