Neuland ist schön. Manchmal beunruhigend, aber schön.
Wenn man nicht rauslas, dass ich vom Cccamp23 derbe begeistert war und es ganz weit vorn lag bei den bisher von mir miterlebten Chaosveranstaltungen, dann hab ich was falsch gemacht. Und wenn ich jetzt mit einem „was geht besser?“ komme, dann mitnichten, weil ich was schlecht fand oder gar scheiße. Jetzt kann man „Jammern auf hohem Niveau“ sagen, aber ich denke, einiges ist an sich eher Nobrainer, ein „Ach, stimmt, sollten wir“ und/oder es macht eh Spaß.
Mehr Wiki, mehr Selbstorga online
Eins von mehreren „Früher war mehr…“ und ja, Dinge ändern sich, aber früher war mehr Wiki, und mir kommt das systemrelevant vor. Das Wiki ist immer einer der „Wir organisieren uns selber“-Knotenpunkte gewesen und das ist es jetzt nicht mehr. Ich würde soweit gehen zu sagen, hier sind auch wirklich faktische Designfehler, denn wenn man Selbstorganisation fördern will, dann braucht man einen anderen Einstieg:
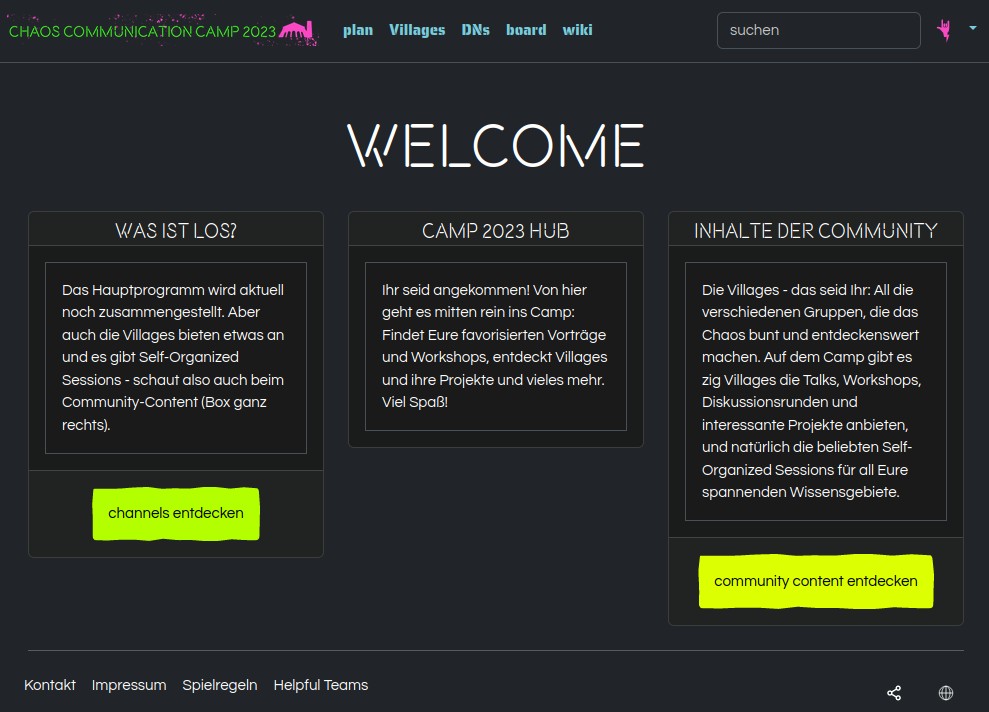
Willkommen bei Finde das Wiki
Das scheint mir in mehrfacher Hinsicht nicht die richtigen Signale zu setzen. Einmal weiß man nicht, wo man da jetzt wirklich „selber“ was machen, eintragen, organisieren kann. Soweit ich sehe, kommt man nur über den „Wiki“-Headerlink ins Wiki, und das fiel durch die Bank extrem spartanisch aus. Was der Unterschied zwischen Wiki und Community Content ist? ich weiß es nicht. Channels? Dito. Wenn ich ne self organized Session machen will: wo schreib ich das hin? Ich weiß nicht, wieviel Mehrarbeit entstand, weil eben alles irgendwie von irgendwem irgendwo angemeldet und eingetragen werden musste, weils die Leute nicht einfach selber machen konnten, meine Vermutung wäre aus der Hüfte aber zumindest „Ja.“.
Und drin bevor kleinlich, was mich wirklich ein wenig vor den Kopf stieß, war das „Ihr“. „Ihr seid angekommen!“, „Die Villages – das seid Ihr:“, „…die beliebten Self-Organized Sessions für all Eure spannenden Wissensgebiete.“ Wer ist ihr, bin das auch ich? Wer sagt das zu mir, ist das wer anderes? Ich beantrage nachdrücklich, in allen Campseiten jegliche Nennung von „Ihr“ durch „Wir“ und analog zu ersetzen. Ernsthaft, Camp ist nicht, dass wer auch immer „euch“ willkommen heißt.
Weiterlesen